Description
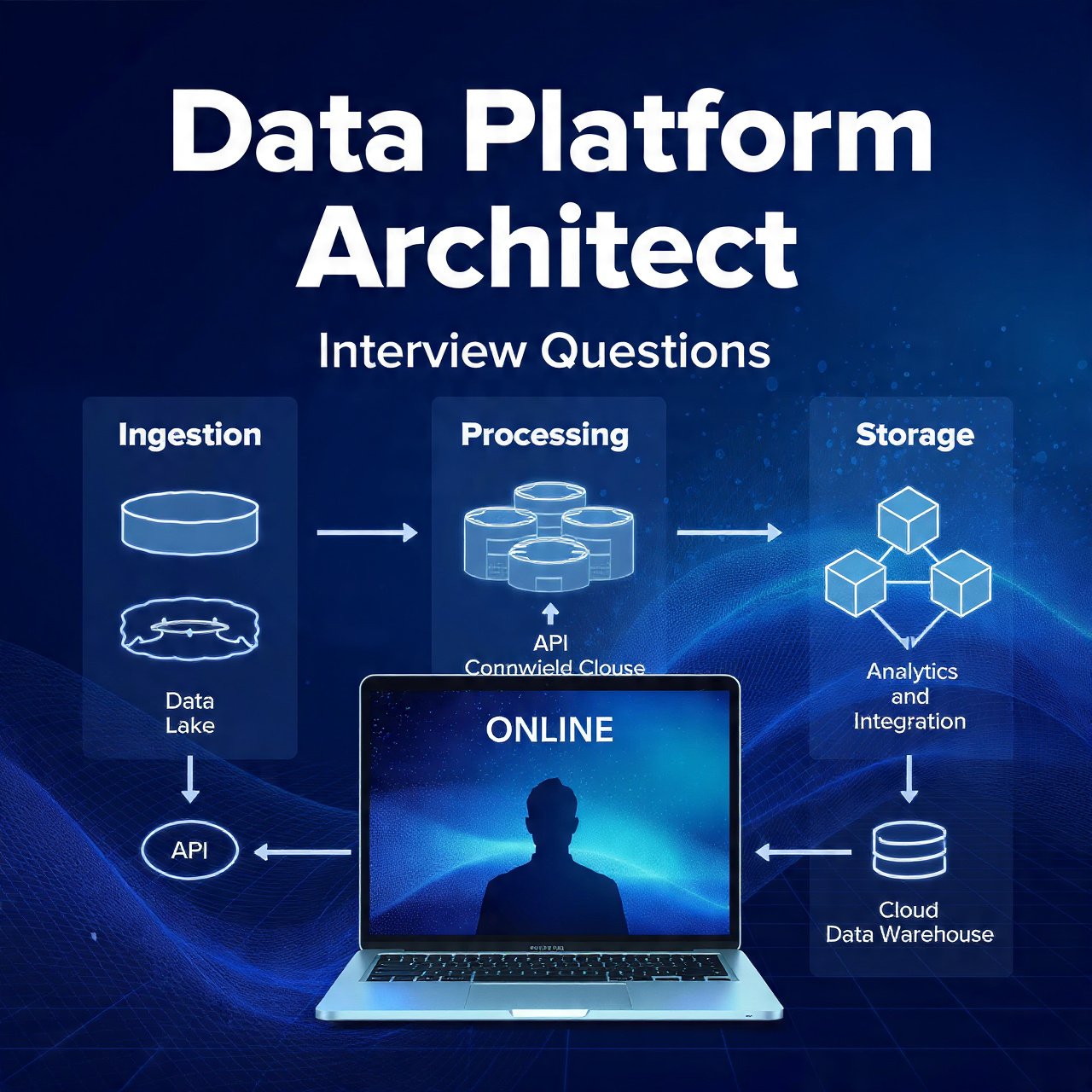
Data Platform Architecture
- Overview: A data platform architecture defines how data is ingested, stored, processed, governed, and served to analytics and ML workloads; modern designs prioritize modularity, scalability, and adaptability.
- Core layers: Ingestion, storage, processing, serving, and governance/observability form the canonical layers of a platform.
- Cloud-first pattern: Most modern platforms are cloud‑native or hybrid, leveraging object lakes, managed warehouses, and serverless compute for elasticity.
- Ingestion features (basic): Batch and streaming connectors, schema detection, lightweight ETL/ELT jobs, and retryable pipelines.
- Storage features (basic): Data lake for raw/curated zones, columnar formats (Parquet/ORC), and lifecycle policies for cost control.
- Processing features (basic): Orchestrated jobs, job scheduling, transformation frameworks (Spark/Databricks), and job lineage tracking.
- Serving features (basic): Data marts, semantic layers, BI endpoints, APIs, and materialized views for low‑latency queries.
- Governance features (basic): Cataloging, metadata management, access controls, encryption, and basic data quality checks.
- Advanced processing: Real‑time stream processing, event‑driven architectures, stateful stream joins, and autoscaling compute pools.
- Advanced storage and performance: Multi‑tier storage (hot/warm/cold), partitioning, compaction, and query acceleration (caching, indexing).
- Advanced governance and security: Fine‑grained RBAC, dynamic data masking, policy as code, lineage for compliance, and automated PII detection.
- Observability and SRE: End‑to‑end telemetry: pipeline SLAs, data freshness metrics, anomaly detection, and cost/usage dashboards.
- Platform automation: CI/CD for data pipelines, infrastructure as code, automated schema evolution, and blue/green deployments for ETL.
- AI/ML enablement: Feature stores, experiment tracking, model serving, and integration of ML pipelines into the platform lifecycle.
- Vendor and pattern choices: Use managed services (e.g., cloud data lake + warehouse) or open‑source stacks depending on cost, control, and compliance needs.
- Operational tradeoffs: Balance latency, cost, consistency, and complexity; choose between ELT vs ETL, streaming vs micro‑batch, and centralized vs federated governance.
- Implement ingestion pipelines, maintain ETL/ELT jobs, manage data schemas, build dashboards, and instrument observability.
- Lead platform architecture, design multi‑region deployments, set governance strategy, optimize cost/performance, and mentor cross‑functional teams.
- Key success factors: Clear data contracts, automated testing, strong metadata, measurable SLAs, and close partnership with product and ML teams.
- Career focus: Junior‑mid engineers deepen pipeline reliability and data modeling; senior architects drive platform strategy, compliance, and scalability.



